
昨天参加了 中关村开源生态论坛暨大模型智能应用技术大会,继PyCon2023后参加的第二个外部会议。
PyCon的主题是”Hello, AI“,我全职做大模型才一个月的时间,参加PyCon时候还没有入职新公司,也第一次听说微软也有类似langchain这样的东西。
当时我问到一个尖锐的问题:“作为普通开发者,我应该在什么时候选择Langchain,什么时候选择semantic-kernel?”,没想到一个月之后,这个问题就变成了我需要在职场里回答的问题。
从现在来看,semantic-kernel是更适合开发企业级应用的,langchain则更适合开发个人的应用。其实也本来就不冲突,semantic-kernel中也可以嵌入langchain的组件和模块,提高大模型应用的开发效率。
再说这次参加的《中关村开源生态论坛暨大模型智能应用技术大会》,很像是一群大模型信徒,攒了一个线下的聚会,在刚建好没多久的中关村论坛大楼里,大家一起分享自己在大模型领域的所思所想。

大会的录象带已经公开了,大家可以在网上观看: https://www.c114.com.cn/live/t799.html
我根据自己的兴趣,重点关注参加了以下议程:
上午
上午的会议比较高屋建瓴,一半是开源生态,一半是大模型相关:
议题有:《The Feature will be Open -共探开源AI》。以前只听说过Apache开源基金会,这个演讲的老哥是LinuxFoundation基金会的(https://www.linuxfoundation.org/projects),等有时间可以研究研究这个组织。
打动我的点:组织或者公司不能招聘全世界所有的聪明人,但是通过拥抱开源,可以让聪明的员工和全世界的聪明人一起工作,同时也能把全世界聪明人,甚至是竞对公司员工的劳动成果也带入到自己的企业里来。和聪明人工作,自己也会变聪明。2024不知有没有时间参与开源活动,这个是对高效能人士的另外一个挑战(第一个挑战是能不能找出时间每天做运动)。

议题有:《深入扩展场景应用:大模型在行业内的探索和实践》。网易23S1做了子曰大大模型之后,S2开始做的一些2C的大模型产品,比如AI外教和家庭辅导老师。听下来感觉2C的技术要求其实比2B是要低一些的,更关注的是业务场景,以及使用相对成熟的技术去解决业务场景里的问题。对比下午的一些创业项目,网易的这几个2C项目的技术风险是相对比较低的。
打动我的点:1)先进词汇,Creative Destruction,创造性破坏。2)AI领域多年没别解决的问题终于被解决了,大模型系统有了知识能力。




议题有:《FlagOpen:大模型时代的Linux,用开源打破壁垒》,这个主要是介绍了 https://github.com/FlagOpen/FlagEmbedding 的一些工作,受限于时间和精力,没有了解太多。
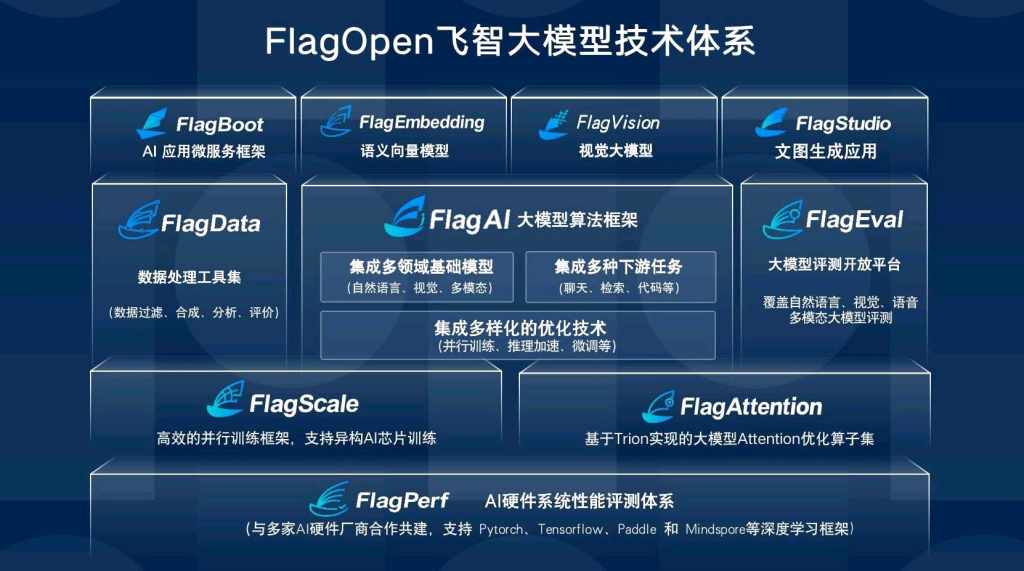


其实我比较关注这种公司的盈利模式,以及可持续发展的路径,一直做开源,不探索商业模式,似乎是个伪命题。
议题有:《开物成务 浪潮开源探索实践》,这个议题主要讲的浪潮做开源数据库的心路历程,中国互联网商场在卷死对方之外还有一个B面,就是开源共建。

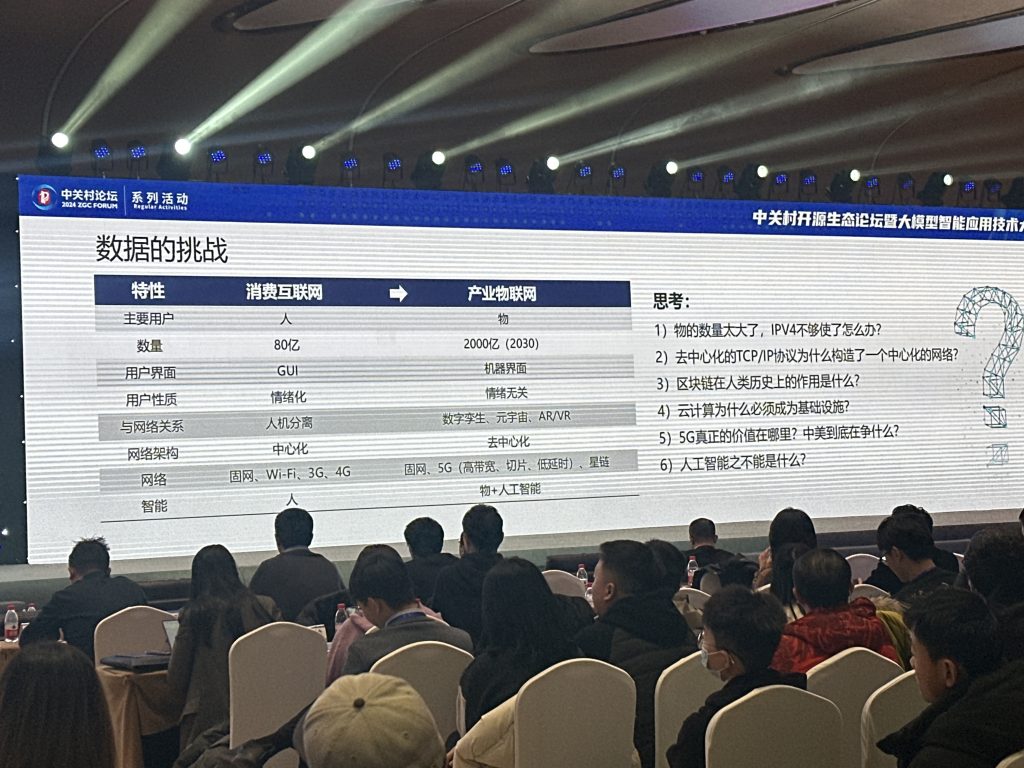

大模型这套东西和造车差不多,一家公司是玩不转的,大家一起玩,把蛋糕做大。
议题有:《Evolution through LLM -大语言模型驱动的技术演进》,这个是前OpenAI的研究员《为什么伟大不能被计划》一书作者Joel Lehman的演讲,是提前录制好的视频。如果以ChatGPT为界,国内大家在做的是成为ChatGPT。这位老哥是基于OpenAI的能力,往前再走了一步或者很多步。里面提到的一些东西可能要翻paper才能讲清楚。有时间可以看看这位老哥具体的研究成果,以及抽时间看看书。

整个上午场听完,感觉大模型还有很多问题需要解决,创新无法用数字完美量化。需要对大模型多一些宽容,也需要对自己多一些宽容。不要被业务压得喘不过气来,需要多一些耐心。
下午
下午感觉智慧和灵感在会场中激荡,信徒们开始讲自己的所思所得。
议题有:《ChatDev的探索与最新实践》,这个项目我之前就有关注过,是清华NLP研究院的大佬们做的。构建了一个由CEO、CTO、程序员、产品经理等组成的智能团队,能根据需求一步一步拆解任务,最后写出项目。和作者交流了一下关于对基座大模型要求的情况,如果基座大模型太差的话,第一步需求拆解就挂掉了,整个项目都跑不起来。未来的一个优化方向是提高群体智能,例如写过俄罗斯方块之后,再写五子棋,是需要能节省token的。
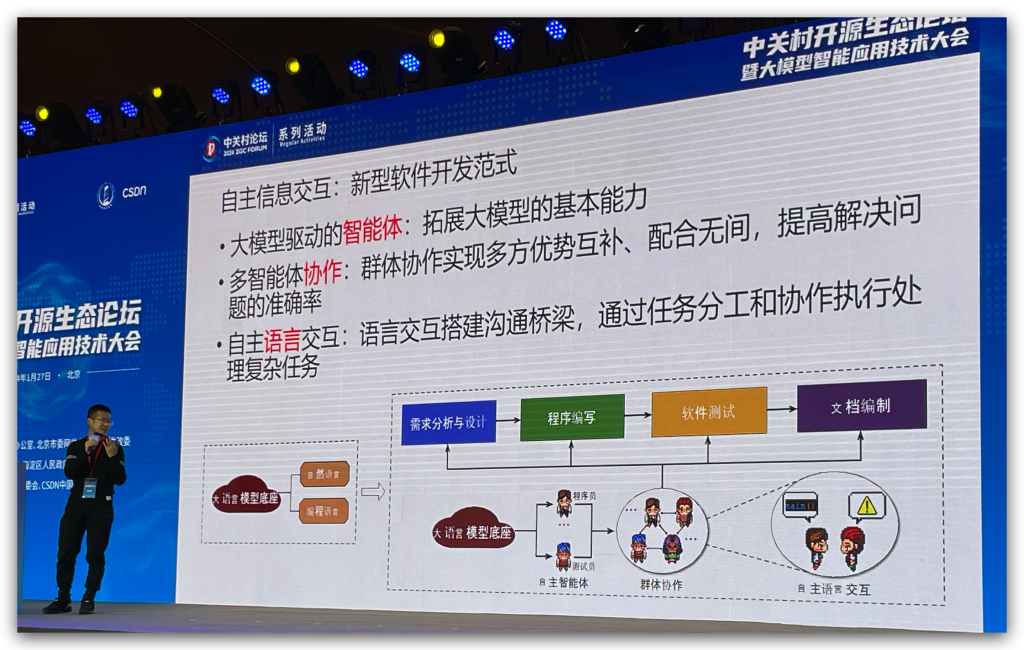
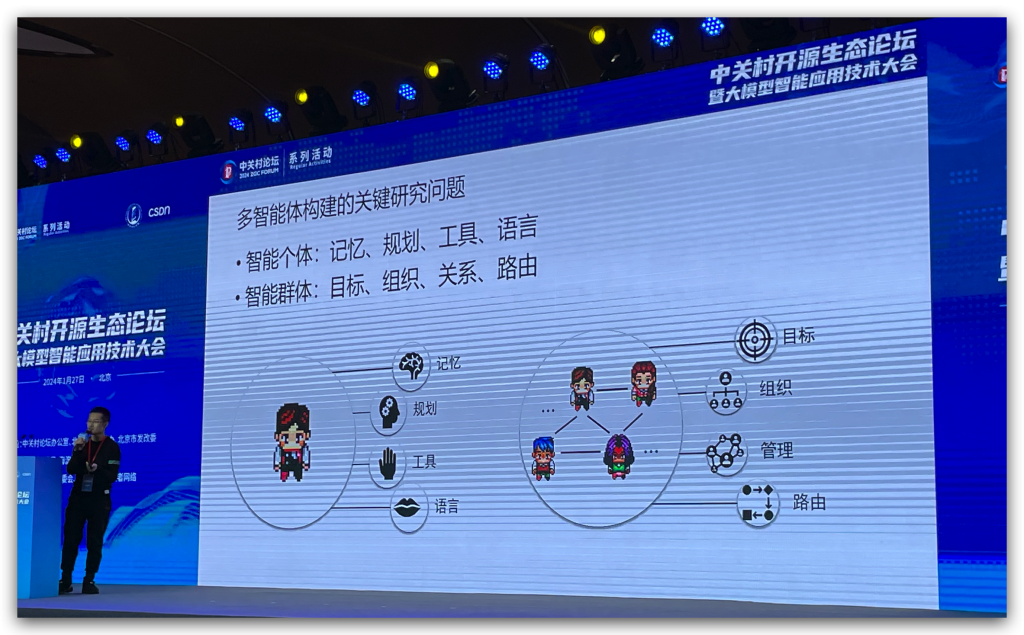

基于瀑布模型去做需求拆分,这个瀑布模型显然是通过人来定义的。

展望:期待群体智能的涌现
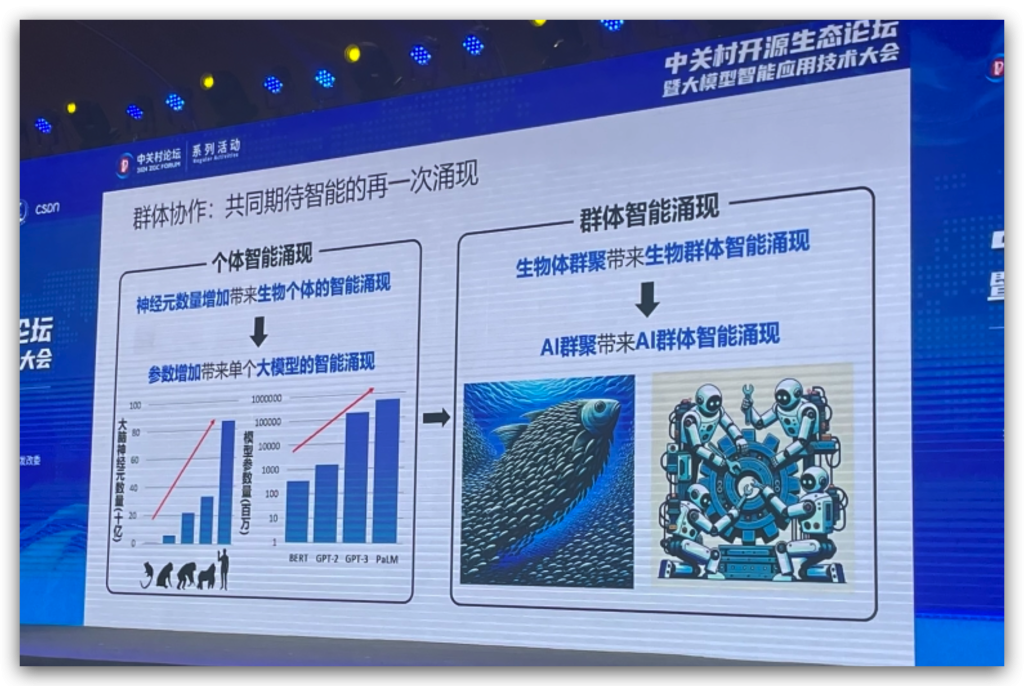
议题有:《大模型驱动的软件研发·进展与展望》,听这个讲座有一种梦回大学校园的感觉,这个王千祥老师讲PPT的感觉太让人熟悉了。想到大学好友也在华为做类似的工作,结果一问竟然是一个团队的,而这个主讲老师也非常了不起,我在网络上找到一份这个老师的公开履历。



以前我觉得学术界和工业界是比较割裂的,这个老师现在华为云的PaaS技术担任创新Lab实验室主任的职位,学术和工业界是可以比较好兼容的。
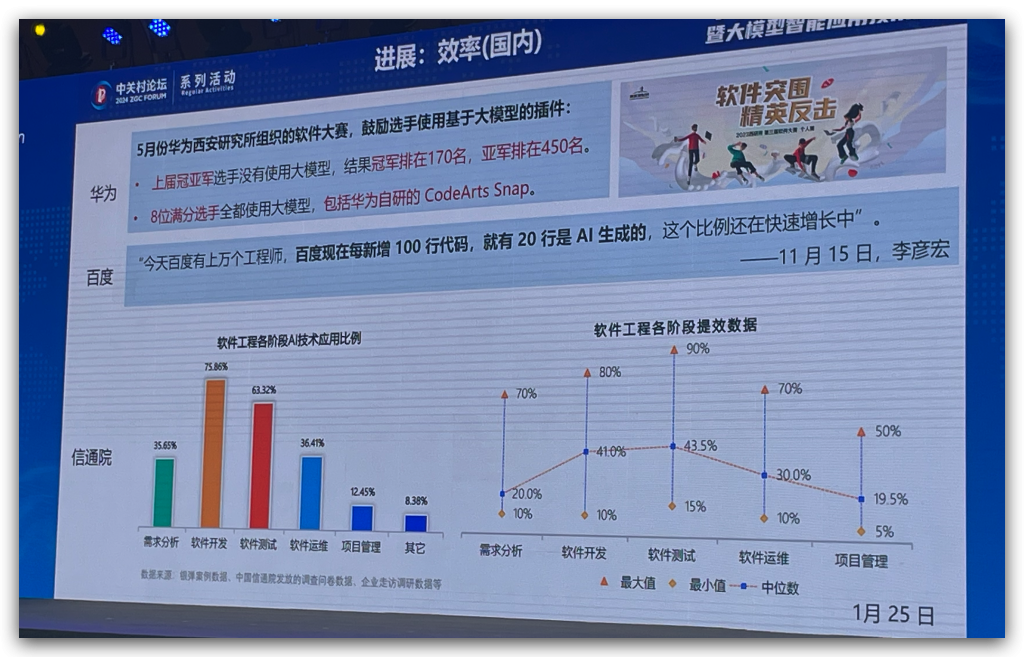
也有一些难点,譬如如何科学的量化软件助手的提效收益等,百度的这个模式就很不错。(后台的非业务部门可能都面临意义和价值的思考吧)
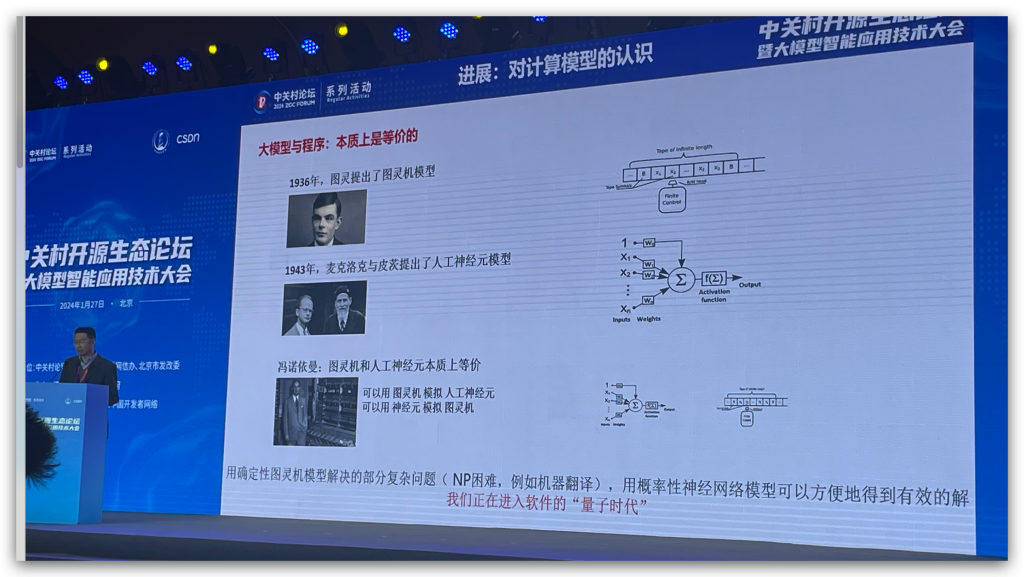
提到一个概念,叫大模型是和程序并列的,都属于软件的关系,我们正进入软件的量子时代。
我觉得这个点非常有意思,周五部门里的技术分享主题是量子计算,提到量子计算机擅长解决RSA大数分解的问题,但是不适用于解决1+1=2的问题,其实大模型也是这样,大模型不适合用于解决圆周率的具体计算问题,但是在一些自然语言的场景,我也看到了大语言模型的一些不同的编程范式。

说大模型带来的新的编程范式,如下图:我对要求大模型为我生成一个可能存在版权风险的图片,这个要是使用传统的编程方法来分析是否存在版权的问题,其实是非常困难的。但是使用大模型的方案来做,只需要询问大模型即可:“你收到的请求是balabalabala,是否有版权风险,如果存在版权风险,你需要输出是或者不是”,然后上层的编程语言再去根据这个判定反馈做进一步处理。



议题有:《AI大模型赋能网络安全》,演讲者是亚信科技5G安全研究院的院长 闫绍华闫老师。23年整个行业都在探索大模型怎么落地网络安全。

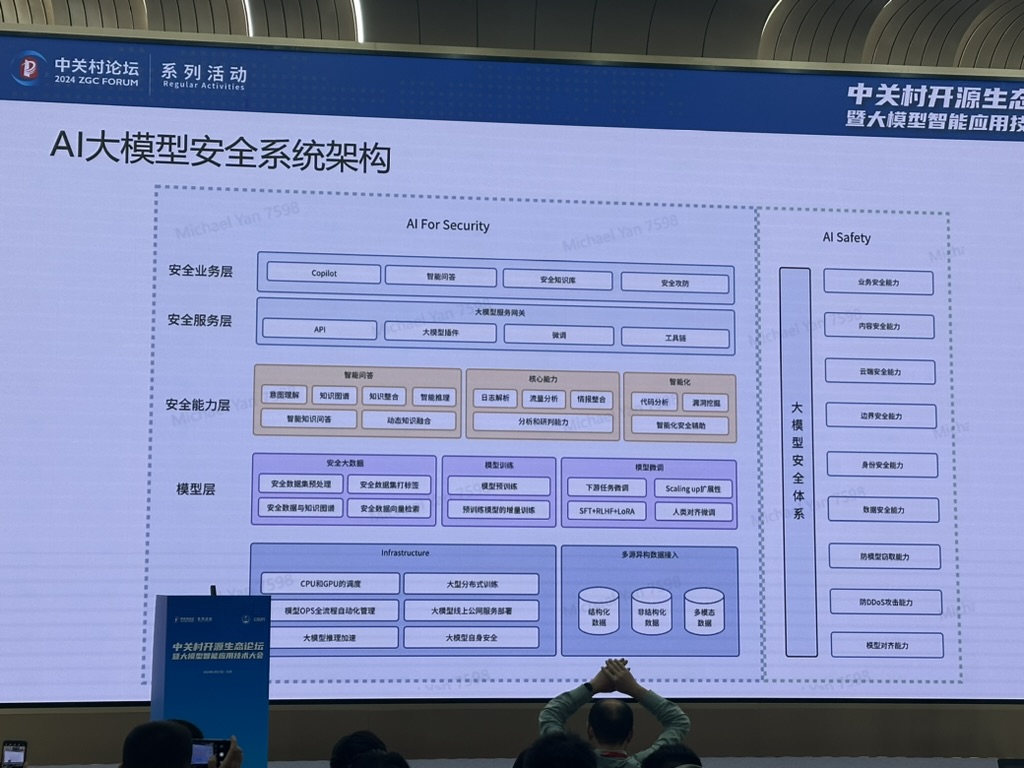

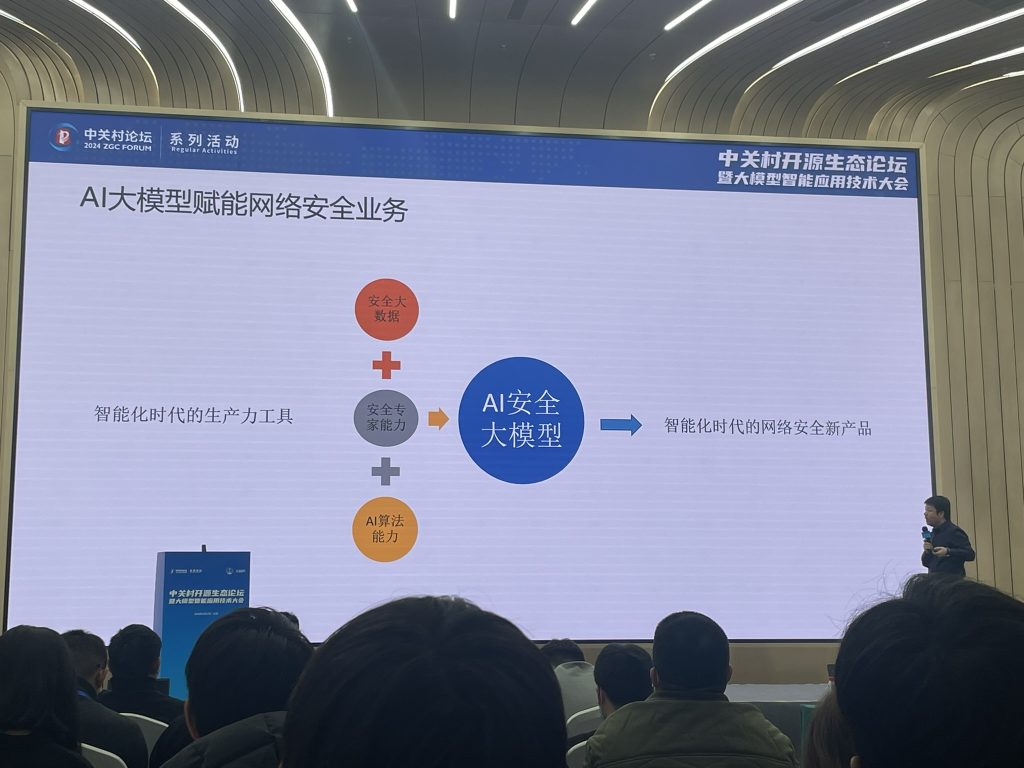

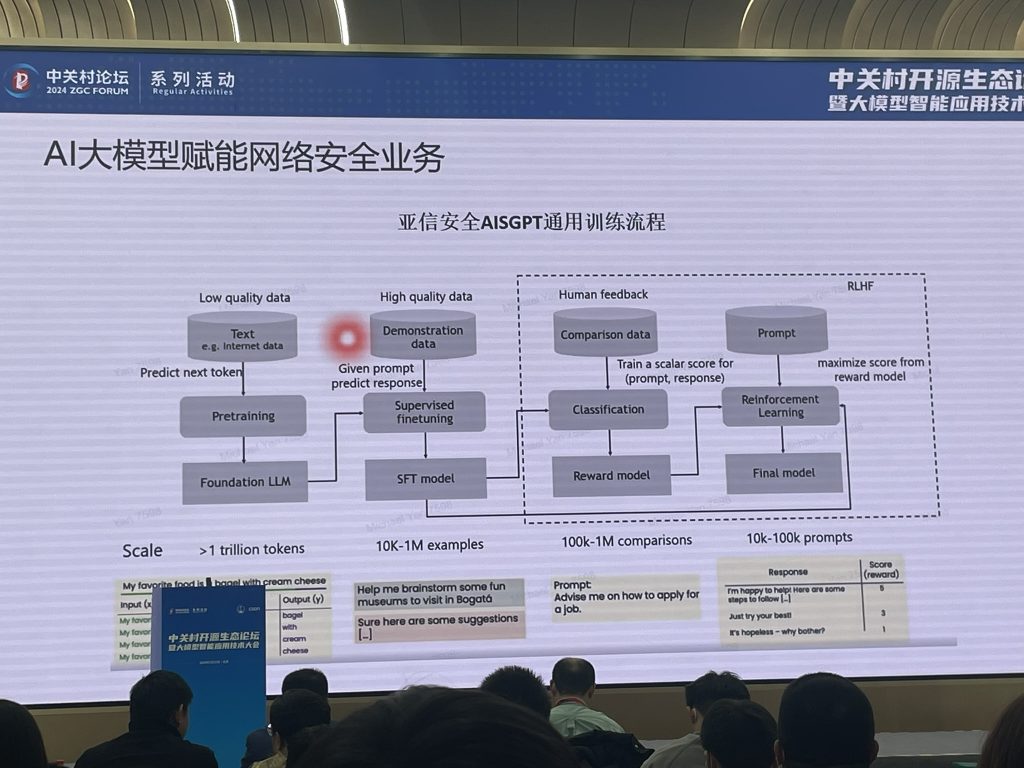
闫老师列举了很多的钉子,期待大模型能提交出令人满意的解法。以及提到了亚信安全自己训练SecGPT。
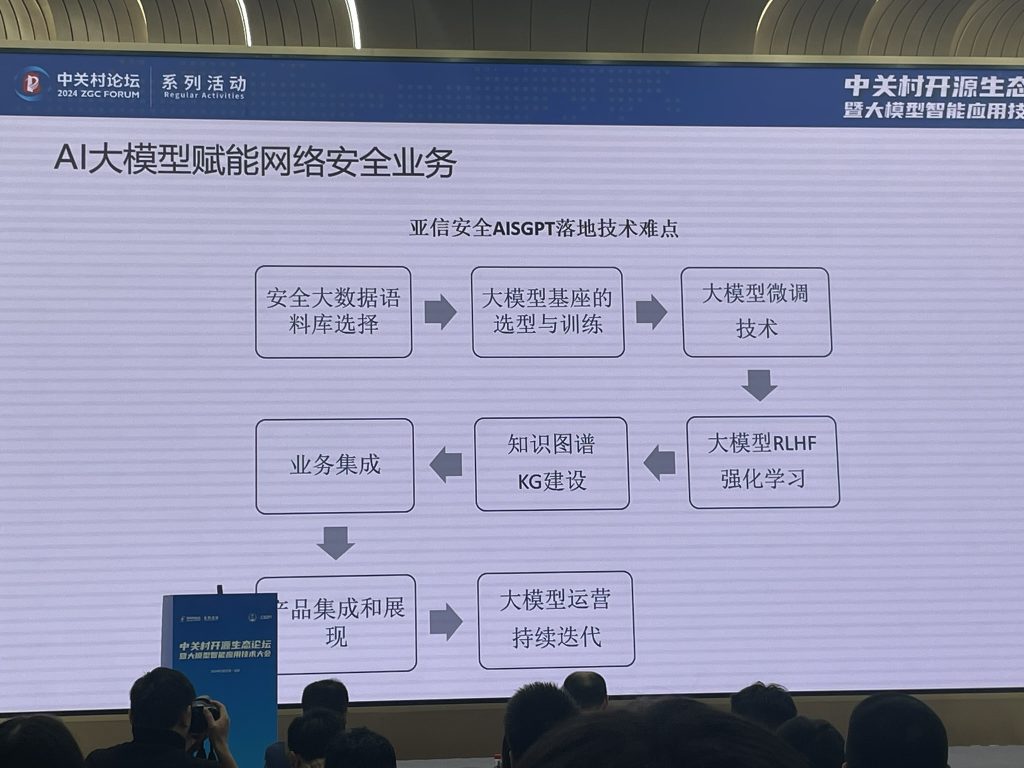
若干的应用场景:

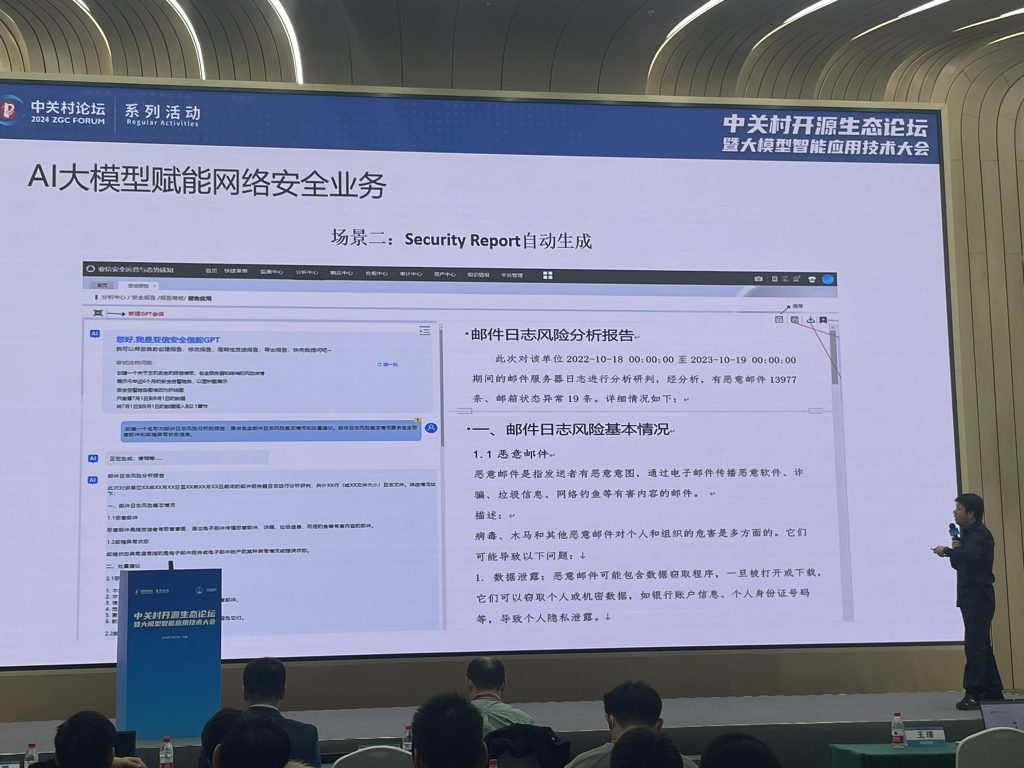


之后闫老师开始讲大模型本身的安全问题,因为和我的工作内容关联不大, 我换了个场继续听。
议题有:《大模型时代的Spring、Byzer三件套》,Byzer是一个开源项目,愿景是让每家公司都可以将自己的业务数据注入进商业或者开源大模型,完成私有化大模型应用。开源地址是:https://github.com/byzer-org/byzer-lang,同时会场外也还有一个做类似事情的创业公司,https://github.com/Maplemx/Agently,打的点是Agent研发框架,大家感兴趣可以关注一下。
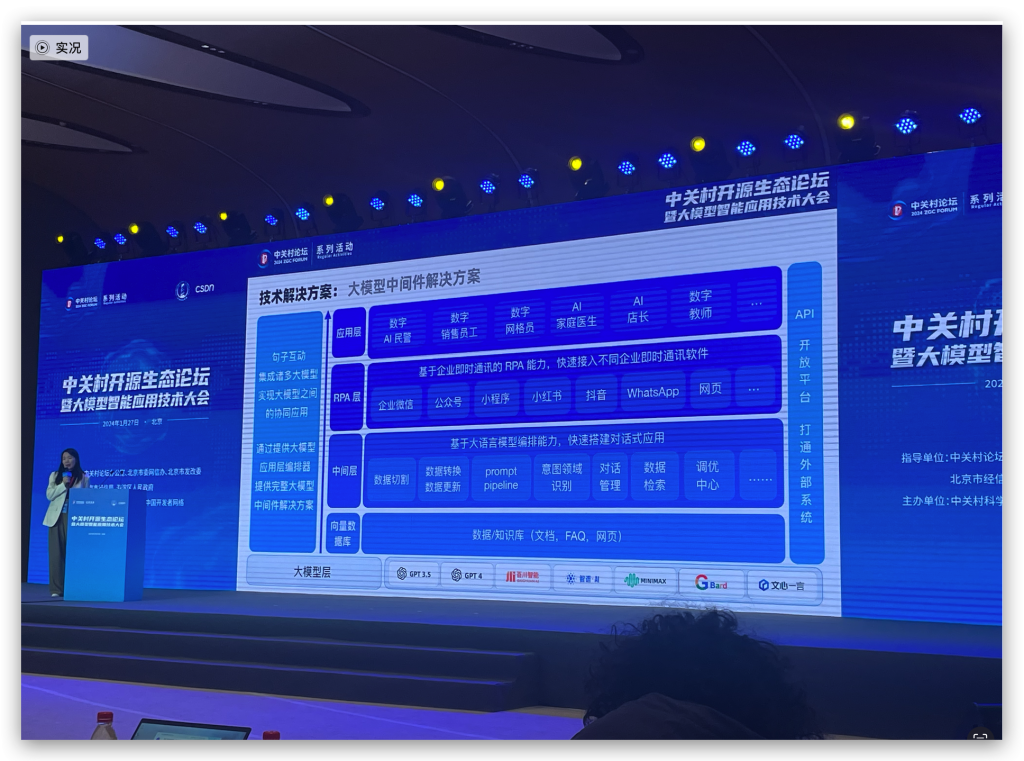
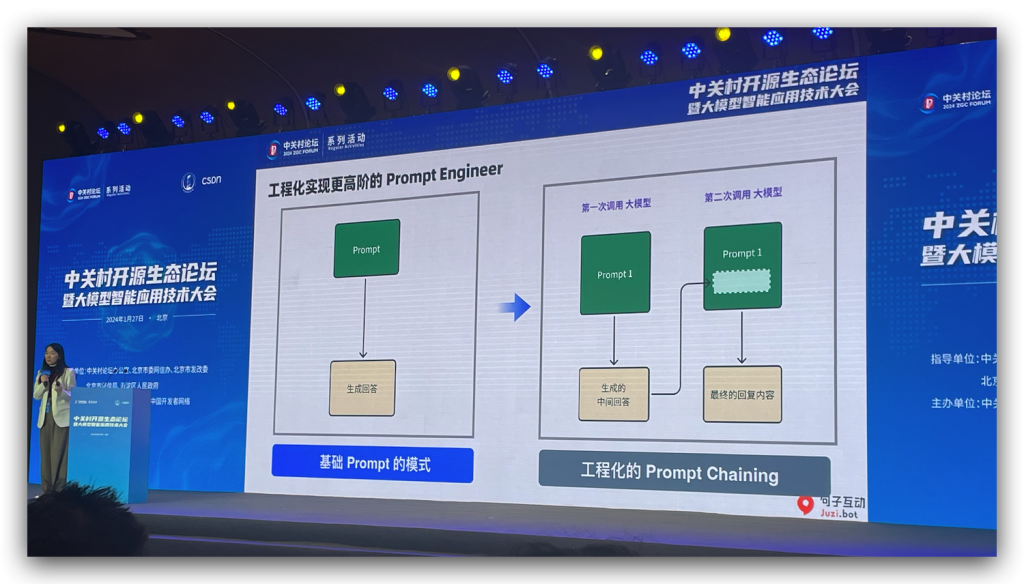
议题有:《大模型的下半场,如何快速构建Agent应用》,这个议题是创业公司句子互动CEO李佳芮的分享。这个小姐姐是和一线业务最近的,因为需要把自己做的大模型应用卖到企业里。在之后的圆桌里还分享了很多金句,一会儿我会再提到。AIGC、私域营销、数字员工,大概这些概念。
提到一个词,叫大模型中间件
搜了一下,原来我多年前看过她的博客,竟然又在现场见到真人了,amazing!https://wechaty.js.org/contributors/lijiarui/
议题有:《如何从零到一构建生成式搜索引擎(Generative Search Engine)》,蓬蓬头小哥就坐在我前面,是Devv AI的创始人兼CEO,公司主要做的程序员垂直赛道的生成式搜索引擎。官方网站:https://devv.ai/zh
提到一个信息信噪比的问题,做大模型RAG应用时要避免垃圾进,垃圾出的问题



提到,RAG其实是让大模型做开卷考试,所以准确retrieve到相关的资料,非常重要。
圆桌

李佳芮分享了两个观点,我也觉得很有趣,和大家也分享一下:
- 需要有插排这个东西。电刚发明的时候,只适配了电灯泡,如果要使用其他电器的话,需要去接灯泡上的电线,直到后来插排被发明了。现在大模型就相当于基础设施(电),以后会有很多电器,也需要有人去做插排。
- 时代的摸索,本身也是有价值的。譬如智能手机刚发明出来的时候,大家做的都是手电筒一类的应用,后来发现这压根就不是智能手机上应用的未来,但是写手电筒应用的这帮老哥们依然很牛逼。
是泡沫还是真的新时代,让我们到24年年底再来回头看吧!
